 kasploosh.com
kasploosh.com
Find Clusters
2012-06-12

Find Clusters GUI
Click to enlarge
CatAmount can find clusters in very little time, even for large data sets or sparse data sets. I developed a new clustering algorithm that takes advantage of natural order in the data.
The definition of a cluster is somewhat elastic, and depends on what distance and time cutoff you choose as part of the definition. The researcher needs to be free to try out different settings, and the GUI makes changing those settings incredibly easy.
It is up to the researcher to determine the scientific time and distance cutoff that defines a cluster for each species being studied. The parameters can be tuned so the software works with different species.
Output
The program returns text output describing each cluster. The user can choose between several kinds of text output, but CSV is the most common.
I used my experience with programmatically creating images to also provide image feedback for every operation. The image feedback is a graphic image that shows the same information as the text, but in a visual format. This allows the user to get a feeling for whether the operation was successful, beyond what can be sensed by just looking at a bank of numbers.
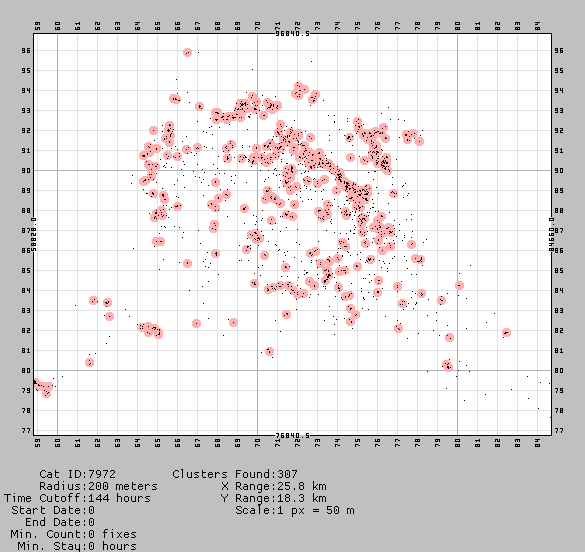
Example image output from Find Clusters
Click to enlarge
Screenshot
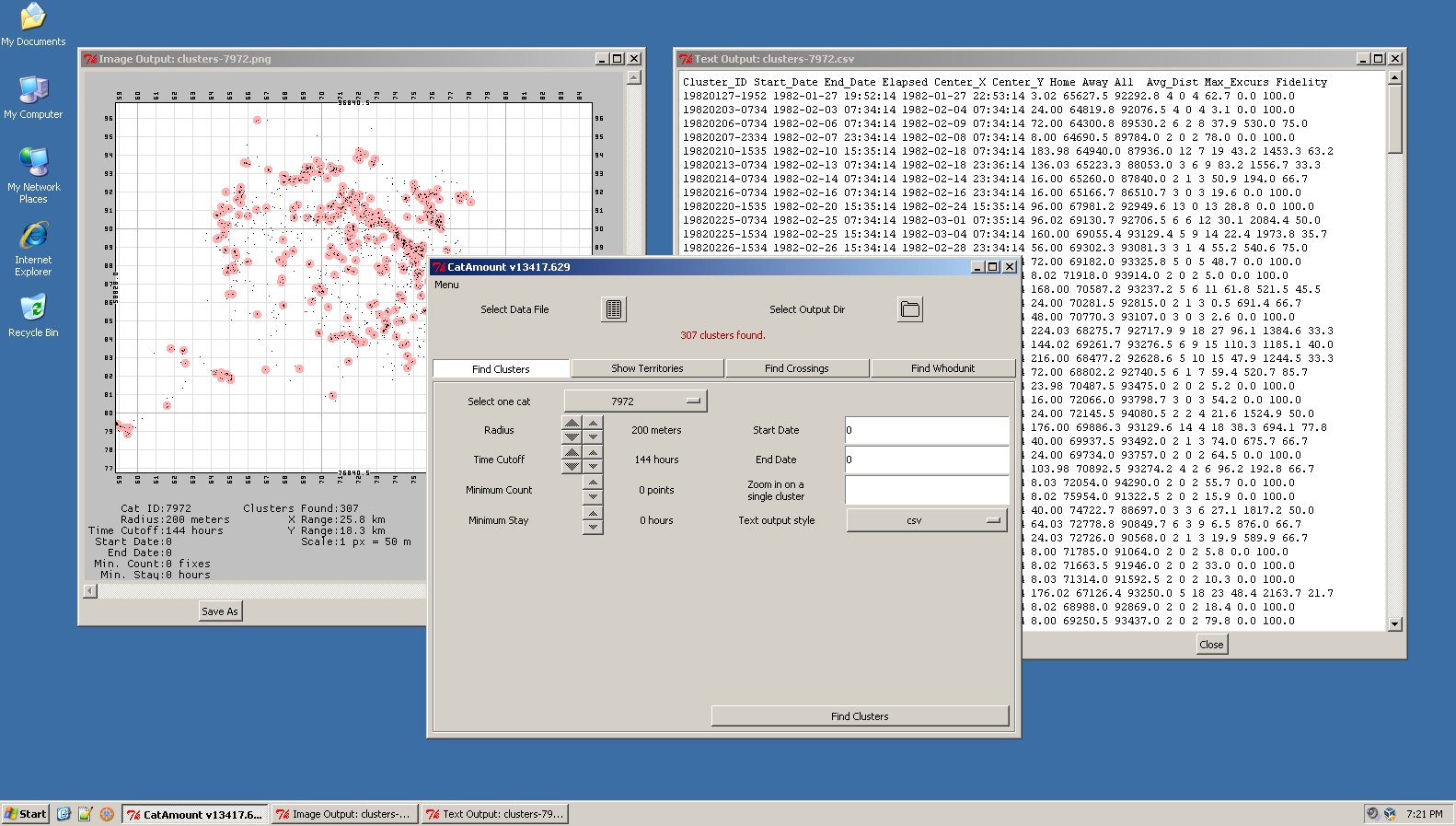
Screenshot of Find Clusters in action.
Click to enlarge